

Voice conversational agents are difficult to commercialize just by connecting STT-LLM-TTS. A structure that integratively understands voice signals, conversation flow, emotions, and context is needed. MAGO has verified the technical conditions needed to advance from an 'AI that has conversations' to an 'AI that understands conversations' through actual collaboration examples over the past two years.
💡 What is a voice conversational agent?
A voice conversational agent refers to an AI system that understands and interacts with human tone, emotion, context, and conversation flow, rather than simply converting speech to text and reading responses.
Over the last two years, MAGO, through collaboration with Naver Cloud and Eisai Korea, has verified step by step what role these voice conversational agents can play in real service environments, and what the market demands.
MAGO's voice technology focuses on analyzing non-verbal information such as emotional changes, speech patterns, and the possibility of cognitive decline from the collected voice signals, beyond sentence meaning analysis.
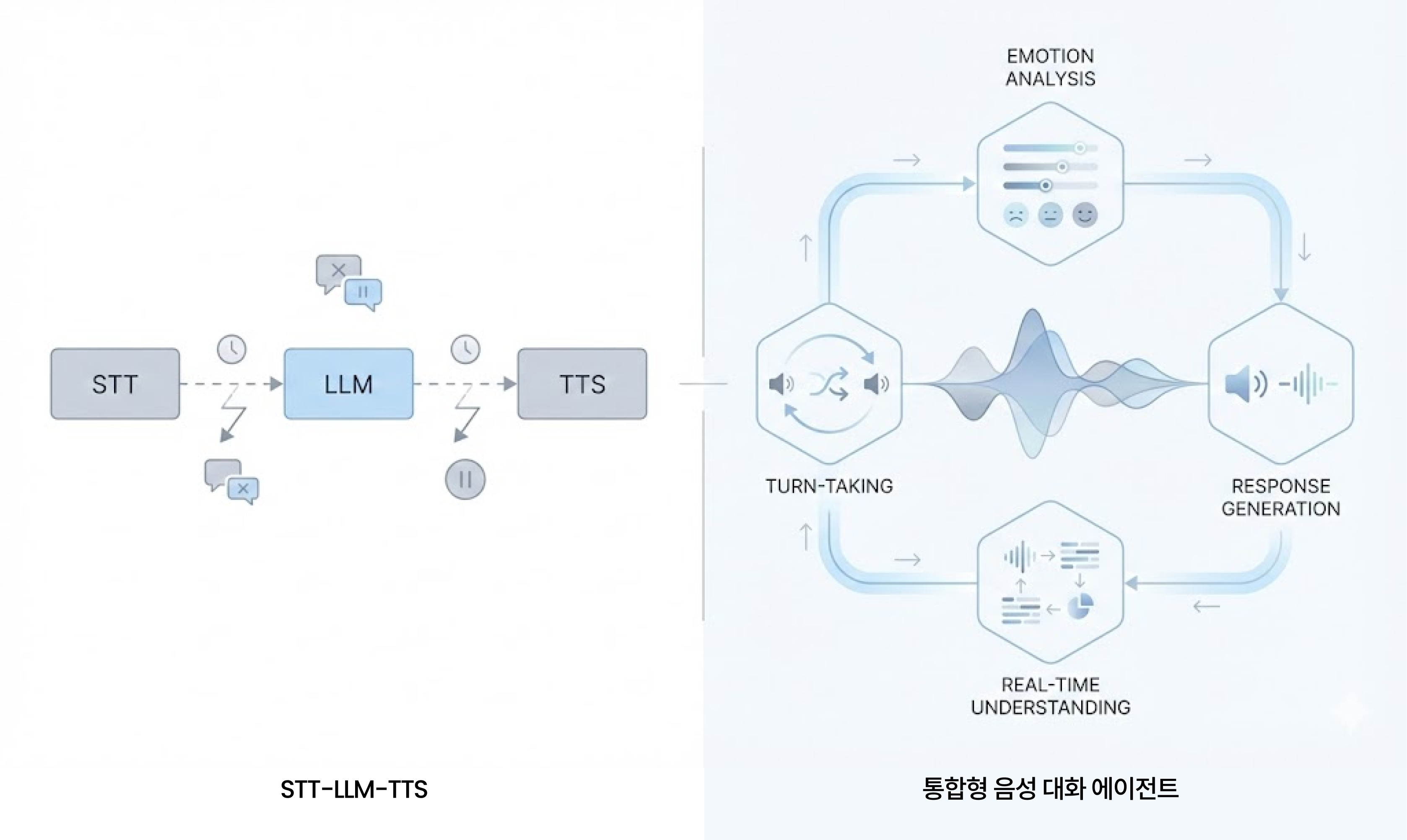
🖇️ Why is it difficult to commercialize with STT-LLM-TTS alone?
In many cases, it is thought that connecting the STT → LLM → TTS structure is enough to implement a voice conversational agent. However, in real service environments, this approach has clear limitations.
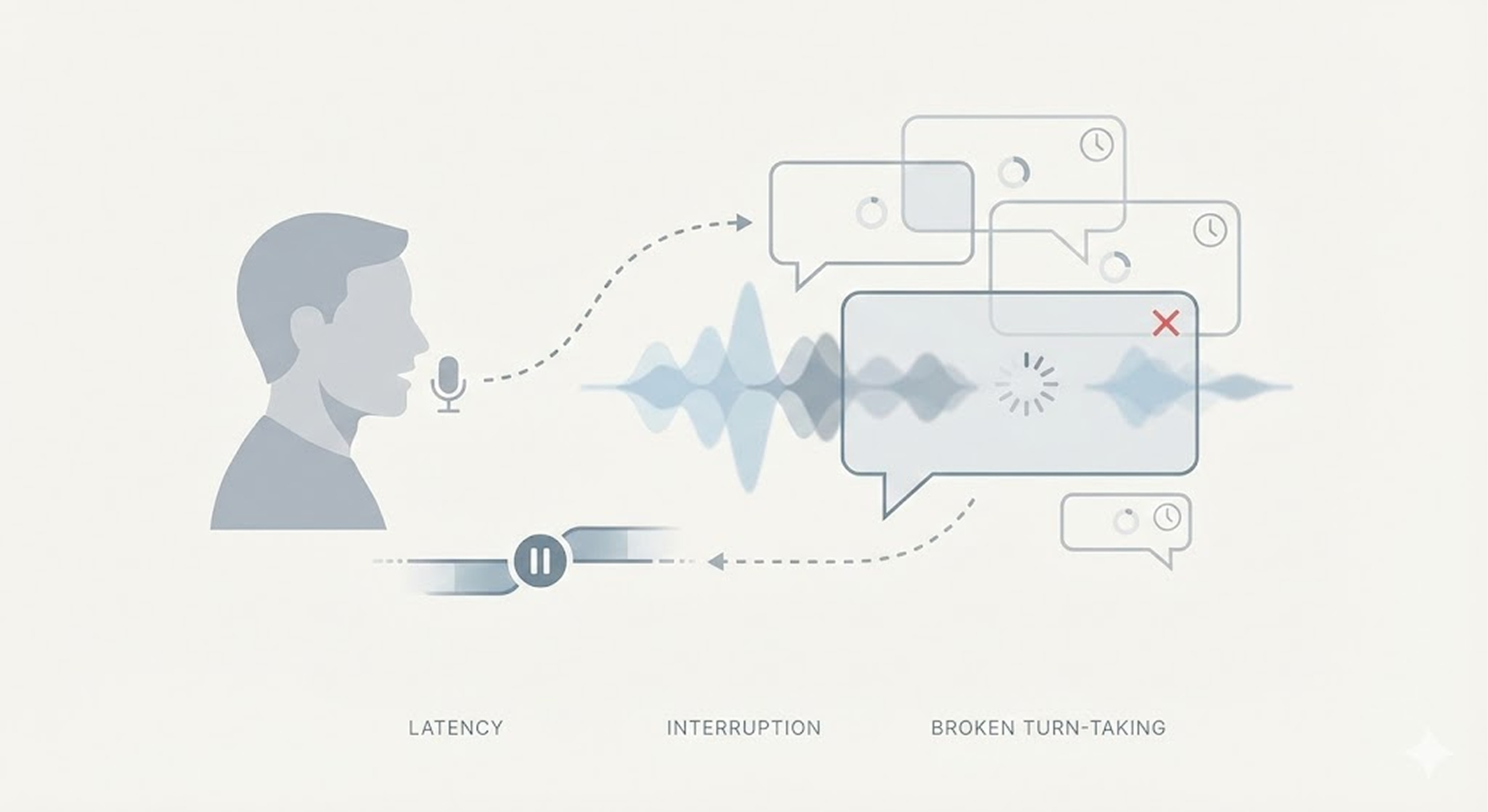
1) The wall of latency
The natural response interval in human conversation is typically 200~500ms. However, sequentially passing through STT, LLM, and TTS accumulates the following delays.
STT: End-pointing delay
LLM: Time taken for inference and first token generation
TTS: Time for voice synthesis and output preparation
If the total delay exceeds 2-3 seconds, users begin to feel anxious about whether their words were heard, easily disrupting the flow of conversation.
2) Problems of turn-taking and silence handling
Simple pipeline structures are typically difficult to handle the natural rhythm of human conversation.
User interrupts (Barge-in)
Intermediate utterances like “um…,” “well”
Pauses while thinking
In this process, if the agent lacks full-duplex processing, sophisticated VAD, and real-time judgment, it easily loses the conversation.
3) Lack of unique vocal information
Text-based LLM does not handle unique vocal information like voice tone, emotion, speaking speed, or tremor.
Even an angry voice is processed as an ordinary sentence
Sadness or fatigue disappears from the meaning
TTS also remains at 'reading aloud' without emotional context
However, in actual conversations, this information serves as an important basis for judgment as much as the meaning does.
🔒 It's not about connecting, it's about 'integrating'
Eventually, the essence of a voice conversational agent is not about connecting models, but whether it can integrate voice signal, recognition, understanding, and reaction into one structure. Whether the service can succeed commercially is decided not by whether it 'processes the user's words,' but whether it can read and react to the user's breathing and state in real-time.
🔎 How MAGO has verified this issue
▶️ Naver Cloud 'CLOVA Carecall' PoC
In 2024, MAGO collaborated with Naver's voice care service 'CLOVA Carecall' to conduct a PoC selecting the possibilities of depression and dementia through phone calls. Carecall is an AI-based care service that regularly calls recipients to check their daily conditions like health, meals, and sleep.
MAGO went beyond simple well-being checks here, verifying whether it could detect cognitive decline and depression possibilities early by analyzing emotional changes, speech patterns, and response delays appearing in the voice signals during the call.
▶️ Collaboration with Eisai Korea & Participation in ILS Tokyo
In 2025, in collaboration with Eisai Korea, MAGO shared the vision of a 'voice-based cognitive function evaluation platform.' Through AI conversations, the language traits, emotion changes, and response patterns of seniors are analyzed, and based on this, cognitive decline possibilities are detected early. During this process, MAGO confirmed one clear fact: Many seniors feel burdened by hospital visits or tests, and they are much more comfortable interacting through natural conversations than manipulating a screen service.
In such environments, voice conversational agents play a role closer to a sensor that detects changes in daily conditions rather than a simple interface. Additionally, due to these technological traits, AI is rapidly spreading in the senior care area in Japan's market, and this was confirmed again in the 2025 ILS event.
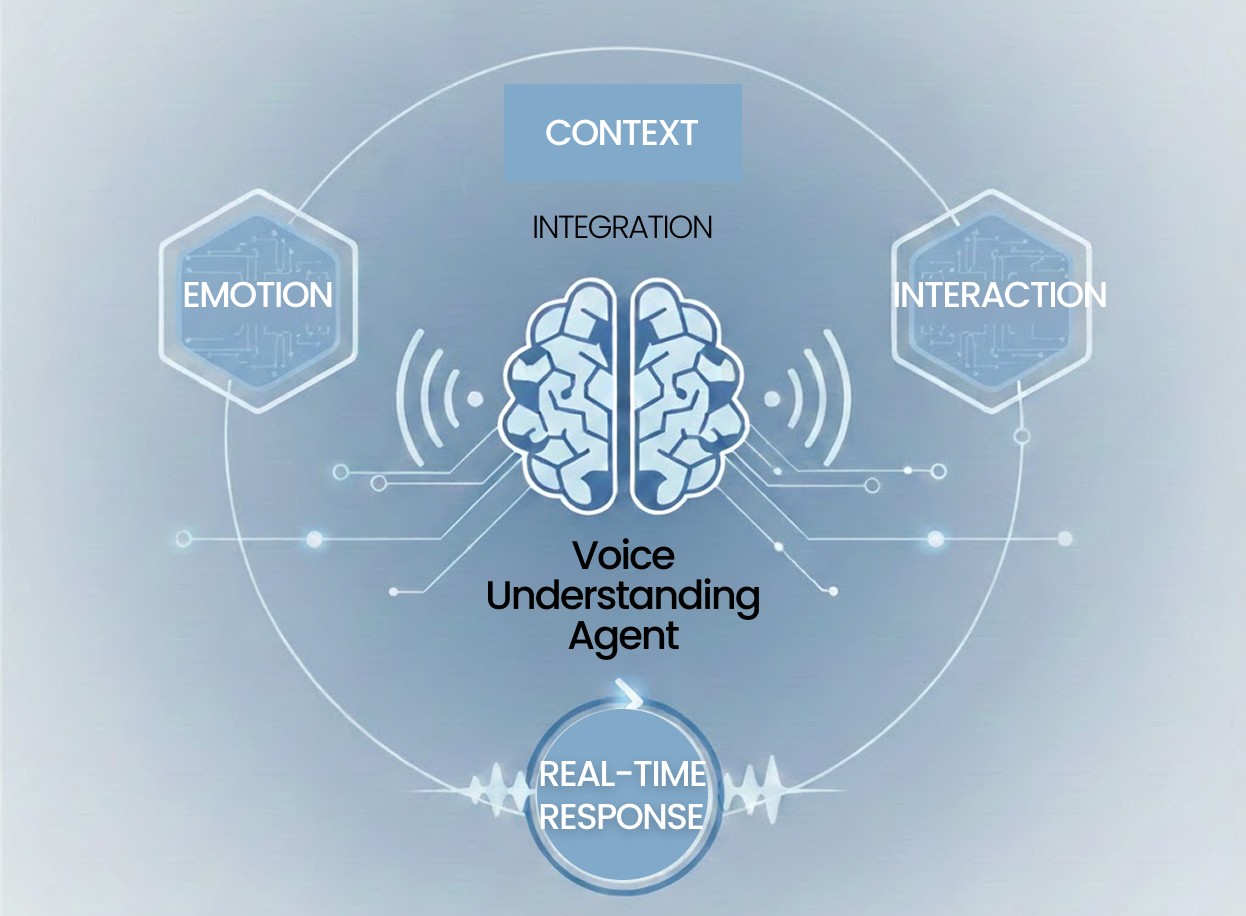
🔈 Voice conversational agents that MAGO is creating
The voice conversational agents MAGO is aiming for are not systems that 'process' conversations, but structures that understand conversations.
Analysis of emotions and states based on voice signals
Understanding speech flow and reaction patterns
Real-time interaction structure
Design that considers not only the cloud but also on-device environments
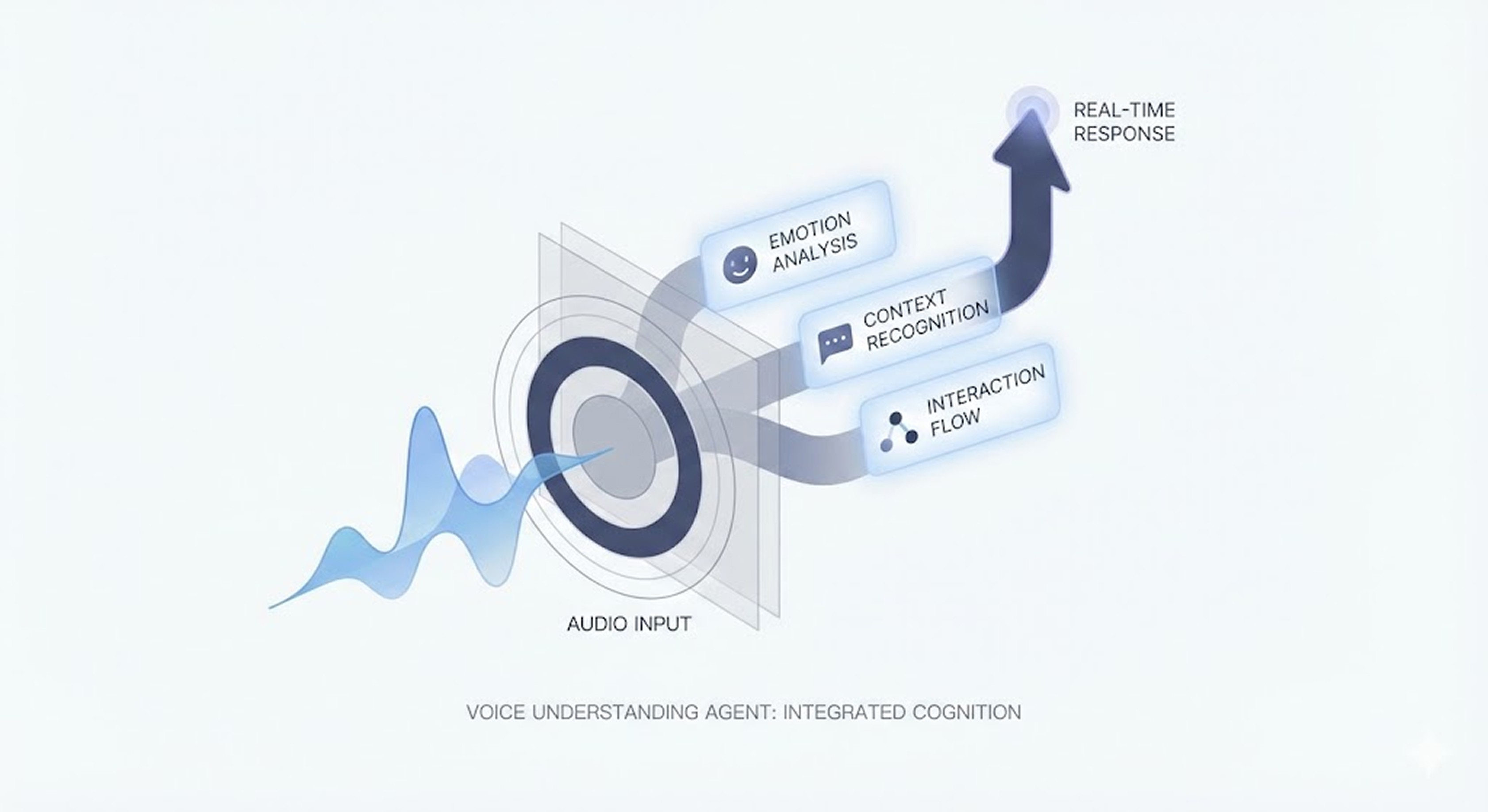
MAGO views voice as "data before text," concentrating on technologically interpreting the human signals contained within. Over the past two years, collaboration examples have gradually proven this direction has meaning in real service environments. In the future, MAGO intends to continue confirming the possibility of developing voice conversational agents from 'systems that have conversations' to 'structures that understand conversations' through collaboration and verification in the field.