

음성 인식(ASR/STT) 기술을 다루다 보면 현장에서 이런 질문을 자주 받곤 합니다. “왜 한국어 STT는 영어보다 오류율이 더 높을까요?”
실제로 한국어 음성 인식은 영어보다 오류율(WER)이 1.5배에서 3배 정도 높게 나타나는 편입니다. 단순히 데이터 양이 부족해서 생기는 격차라고 생각하기 쉽지만, 실무적으로는 한국어의 언어적 구조도 주요한 원인입니다.

출처 : https://elevenlabs.io/speech-to-text/english

출처 : https://elevenlabs.io/speech-to-text/korean
*WER이 10.7로 영어대비 3배 가량 높은 걸 볼 수 있음
🧐 한국어 음성 인식이 어려운 기술적 이유
현장에서 마주하는 한국어의 장벽은 몇 가지 뚜렷한 특징이 있습니다.
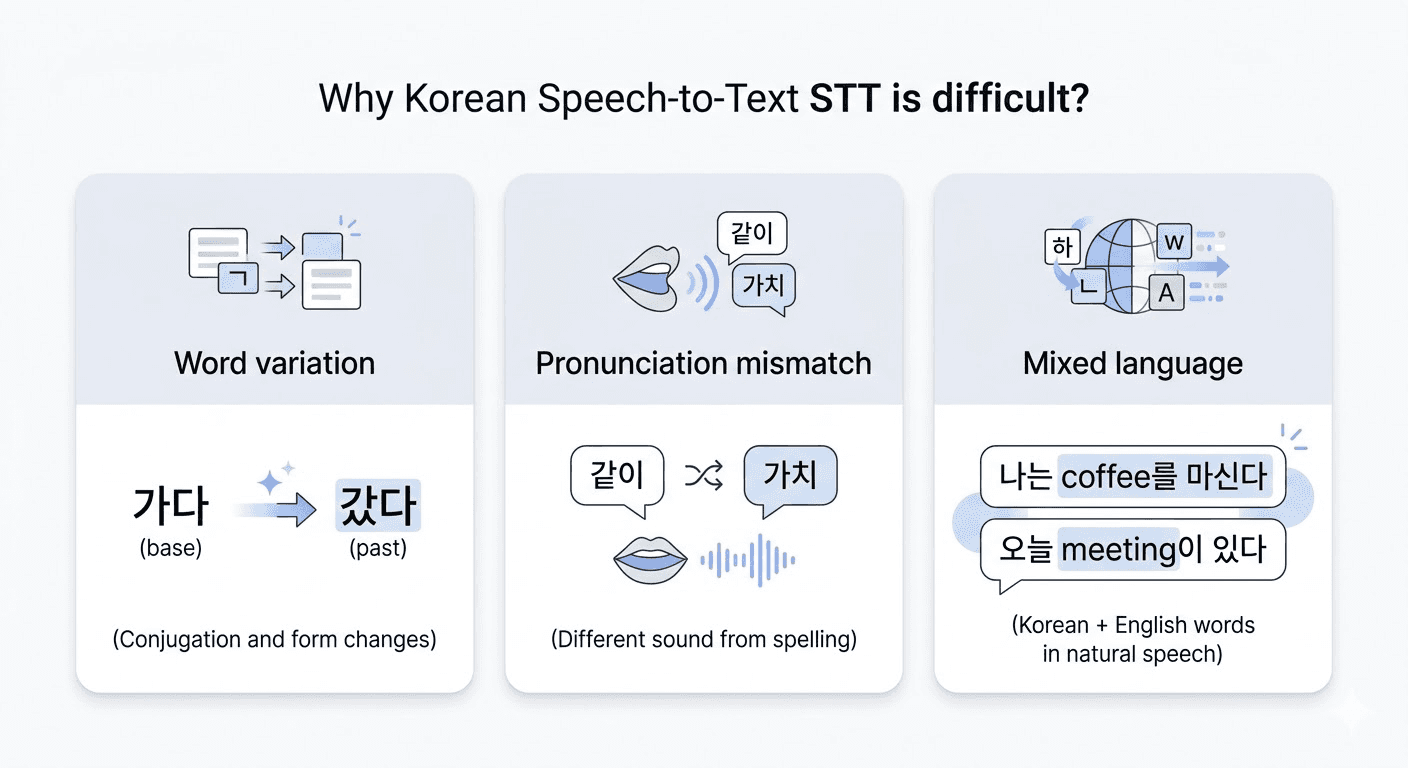
변화가 많은 단어 구조 (교착어): 영어는 단어가 비교적 독립적이지만, 한국어는 어간 뒤에 조사와 어미가 계속 결합하는 교착어입니다.
가다하나도갔다, 갔었다, 갔었습니다처럼 변형이 다양하죠. 표준국어대사전 단어만 51만 개가 넘는데, 여기에 외래어와 형태소 분석까지 고려하면 모델이 처리해야 할 정보량이 매우 방대해집니다.표기와 발음의 불일치 (음운 변화):
국밥[국빱],같이[가치]처럼 한국어는 실제 음성과 글자가 일치하지 않는 경우가 많습니다. 음성 신호를 텍스트로 옮길 때 이러한 발음 규칙(음운 법칙)을 정교하게 반영하지 못하면 오인식으로 이어지게 됩니다. 영어에도 불규칙 발음은 있지만, 한국어의 음운 변화는 케이스가 훨씬 방대하고 체계적으로 작동합니다. 그만큼 모델 입장에서는 학습 난이도가 높습니다.외래어 및 영어 혼용 비중의 급증: 한국어 모델이 영어 단어를 처리하려면 두 언어의 발음 체계를 동시에 이해해야 하는데요. 게다가 같은 외래어도 사람마다 발음이 달라지는 경우가 많아(마케팅 vs 마게팅, 데이터 vs 데이타) 일관된 인식이 더 어려워집니다.
🔎 마고(MAGO)가 음성 모델을 설계하는 방식
세 가지 문제의 공통점이 있습니다. .데이터는 많을수록 도움이 되지만, 데이터 양만 늘려서는 해결이 안 된다는 점입니다. 양적인 확대만으로 성능이 비례해서 좋아지지는 않습니다. 마고는 한국어의 언어 구조와 음성 신호의 특성을 모델 설계 단계부터 반영하는 데 집중합니다.
마고(MAGO)는 이 지점에서 출발합니다.
음성 최적화 설계: 한국어의 복잡한 발음 변화를 포착할 수 있는 임베딩(Embedding) 모델을 구축했습니다.
음성 신호 전처리: 소음 속에서 목소리만 정밀하게 골라내는 음성 강조(Speech Enhancement) 및 음성 분리 기술을 통해, 성능의 정확도를 안정적으로 유지합니다.
한국어 맞춤형 토크나이저(Tokenizer): 우리말의 형태소 특성을 반영해 단어를 분리하고 처리하는 방식을 사용합니다.
🔈 STT, 그 다음 단계
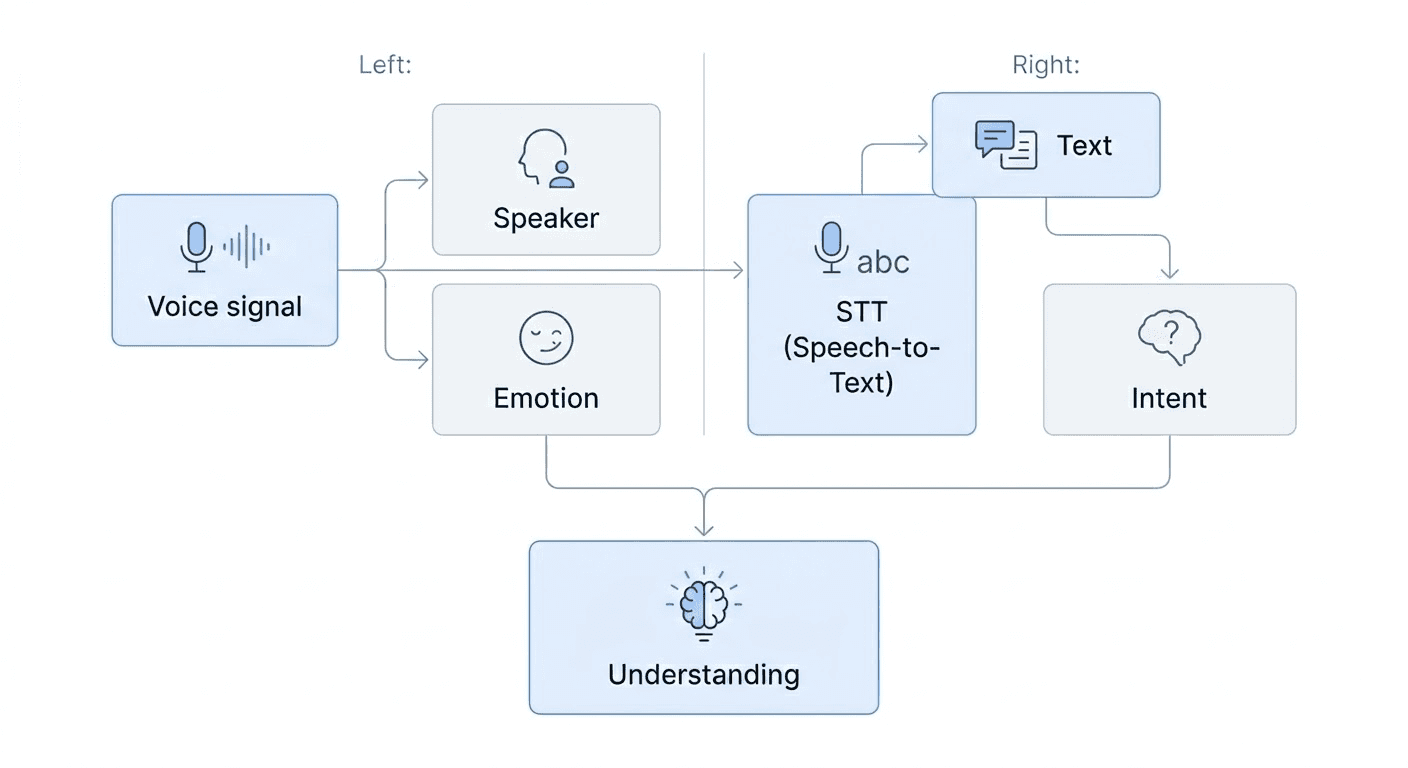
많은 음성 인식 서비스가 STT 정확도에 집중하지만, 실제 비즈니스 현장에서는 텍스트 정확도만으로 충분하지 않은 경우가 있죠. 대화의 맥락을 명확히 파악하기 위해 "누가 말했는지(화자 정보, Diarization)"나 "어떤 톤으로 전달되었는지(Emotion)" 같은 데이터가 분석의 정밀도를 높이는 데 활용되기 때문입니다.
마고는 안정적인 인식 성능을 기반으로 하되, 음성 데이터를 다각도로 분석해 비즈니스에 필요한 입체적인 정보를 제공하는 '음성 이해(Voice Understanding)'를 지향합니다.
화자 분리나 감정 분석 같은 정보는 음성(Signal)에서 직접 추출하고, 대화의 의도(Intent)는 분석된 텍스트에서 파악합니다. 이렇게 각 데이터가 유기적으로 맞물려야 신뢰할 수 있는 분석 결과가 나올 수 있습니다.
💡 음성을 음성답게 이해하는 기술
한국어 STT의 난이도는 적은 데이터의 문제뿐만 아니라, 한국어 구조와 음성 신호 자체가 복잡하기 때문이기도 합니다. 결국 이러한 특징들을 모델 설계에 어떻게 녹여내느냐가 기술력의 핵심이라고 볼 수 있는데요.
마고는 단순히 받아쓰기를 넘어, 음성 데이터에서 비즈니스에 유용한 정보를 찾아내는 솔루션을 만듭니다.
한국어 환경에 맞는 음성 인식 도입을 고민하고 계시나요? 구체적인 적용 방안이나 기술적 최적화에 대해 고민하고 계신다면, 언제든 마고와 함께 이야기를 나누어 보세요!