

음성 AI를 현장에 적용하다 보면 자주 마주치는 상황이 있습니다.
콜센터는 상담사와 고객, 두 명이죠. 8명 이상이 참여하는 간담회 녹취를 분석해달라는 요청이 들어오면 어떻게 해야 할까요?
고성능 E2E(End-to-End) 화자 분리 모델은 최대 4명까지만 지원합니다. 5번째 화자부터는 묵음 처리되거나 다른 화자에 합산됩니다. 클러스터링(Clustering) 기반 모델인 pyannote는 10명까지 지원하지만, 속도와 상용 환경에서의 성능 면에서 실제 서비스 적용에 한계가 있습니다. 결국 "속도와 성능을 확보하면서 8명 이상을 지원하는 E2E 모델"은 존재하지 않았습니다.
이 문제를 해결하기 위해 MAGO 마고가 연구를 시작했고, 그 결과물을 공개합니다.
🔎 화자 분리(Diarization)란?
화자 분리는 "누가 언제 말했는가"를 자동으로 구분하는 기술입니다. STT가 목소리를 텍스트로 옮기는 '받아쓰기'라면, 화자 분리는 그 텍스트에 이름표를 다는 과정입니다. 이 둘이 결합해야 비로소 '대화 데이터'로서의 가치가 생깁니다.
두 기술이 결합될 때 비로소 실제 비즈니스에서 쓸 수 있는 형태가 됩니다. 콜센터 상담 분석에서는 상담사 발화와 고객 발화를 구분해야 각각의 감정 상태나 응대 품질을 따로 평가할 수 있습니다. 회의 녹취에서도 "이 발언이 누구의 것인지" 추적되지 않으면 분석의 의미가 크게 떨어지죠.
🧐 왜 4명이 한계일까요?
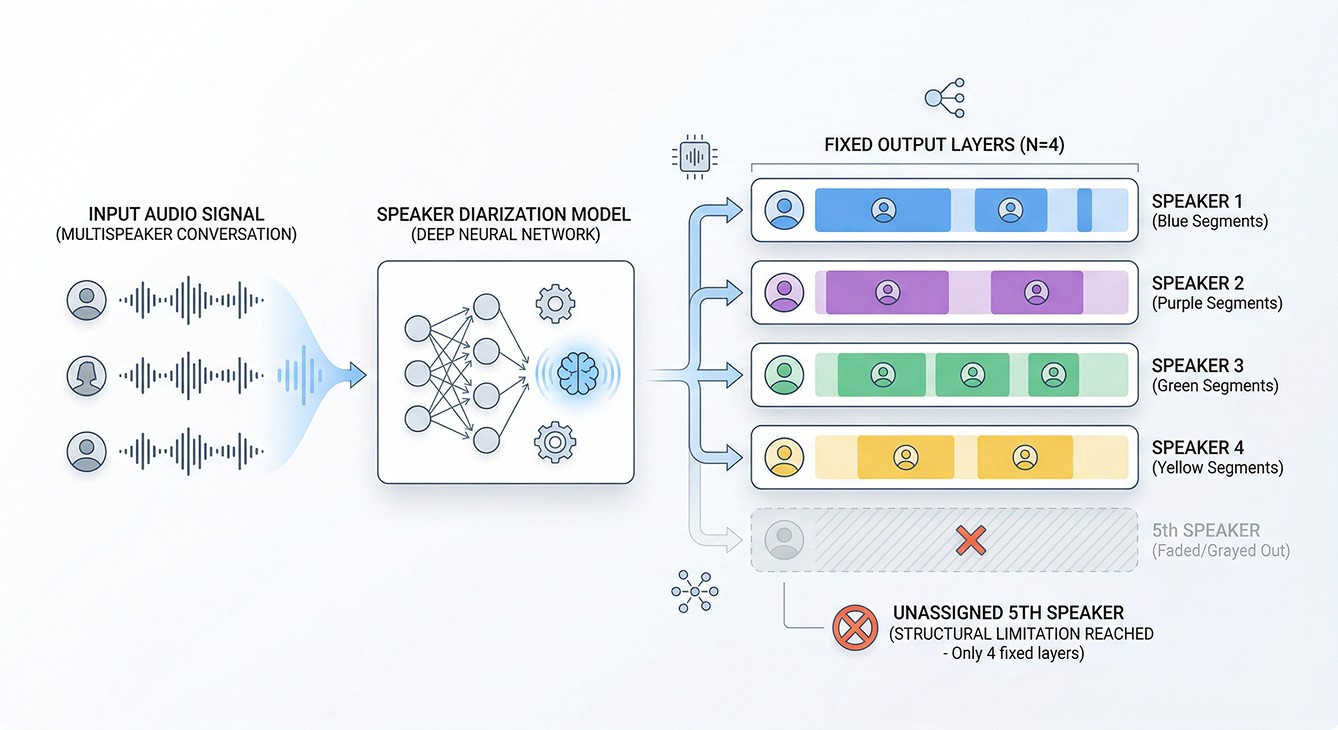
현재 공개된 고성능 화자 분리 모델들은 대부분 최대 4명(4-speaker)으로 설계되어 있습니다. NVIDIA NeMo의 Streaming Sortformer 모델도 마찬가지인데요.
이유는 구조적인 제약입니다. 모델 내부에 화자 수만큼의 출력 레이어가 필요하고, 이를 늘리려면 아키텍처 수정과 함께 대규모 재학습이 필요합니다. 무엇보다 실제 다화자 학습 데이터를 확보하기가 매우 어렵죠.
MAGO 마고가 실제로 서비스하는 현장을 보면 4명 초과 케이스가 적지 않습니다.
기업 간담회, 교육 콘텐츠 제작 환경: 8명 이상
콜센터 채널 통합: 상담사·고객·ARS 등 복합 화자 구성
회의 전사 서비스: 다수 참여자가 동시에 발화하는 환경
4명 제한은 이 시나리오들에서 바로 문제가 됩니다.
🔈 기존 성능을 유지하면서 화자 수를 확장하기
MAGO 마고는 NVIDIA NeMo의 Streaming Sortformer를 베이스로, 최대 8명까지 지원하는 모델을 개발했습니다.
가장 어려운 문제는 두 가지였는데요. 바로 학습 데이터 확보와 기존 성능 유지입니다.
학습 데이터 문제는 합성 데이터로 해결했습니다. AI-Hub의 다화자 음성합성 데이터(3,400명 이상의 한국어 화자, 약 1만 시간 분량)를 기반으로, NeMo의 데이터 시뮬레이터를 커스터마이징하여 다양한 화자 수와 발화 패턴을 가진 합성 대화 데이터를 생성했습니다. 여기에 실제 회의 환경의 노이즈가 포함된 데이터를 소량 혼합해, 클린 환경에만 최적화되는 오버피팅을 방지했습니다.
기존 성능 유지 문제는 두 가지 기법으로 해결했습니다.
첫째, 새로 추가하는 출력 레이어를 단순 랜덤 초기화하지 않고 SVD 기반 직교 초기화(Orthogonal Initialization)를 사용했습니다. 기존 가중치 행렬을 SVD 분해한 뒤, 기존 화자들의 표현 공간과 수학적으로 직교하는 방향으로 새 레이어를 초기화합니다. 이렇게 하면 새로 추가된 화자 차원이 기존 2~4명 화자 인식에 미치는 영향을 최소화할 수 있죠.
둘째, 기존 레이어와 신규 레이어에 서로 다른 학습률(Split Learning Rate)을 적용했습니다. 기존 레이어는 낮은 학습률(1e-5)로 기학습된 표현을 보존하고, 신규 레이어는 높은 학습률(1e-4)로 빠르게 새 화자 범위를 학습하도록 설계했습니다.
🖇️ NVIDIA NeMo Speech 팀과의 논의
이번 모델을 HuggingFace에 공개한 후, NVIDIA NeMo Speech 팀으로부터 연락을 받았습니다. 화자 분리와 음성 인식 분야를 담당하는 연구팀이 MAGO 마고의 모델을 발견하고 기술적인 논의를 제안해왔고, 이후 양사는 평가 방법론, 학습 데이터 구성, 다화자 스트리밍 최적화 전략 등을 함께 논의했습니다.
이 과정에서 평가 데이터셋에 대한 중요한 인사이트도 얻었습니다. 인터넷에 통용되는 일부 AMI RTTM 파일은 원본 XML 변환 과정에서 무음 구간이 화자로 잘못 레이블링되어 있어 평가 지표가 왜곡될 수 있습니다. 정확한 평가를 위해서는 공식 배포 경로의 정확한 RTTM 파일을 사용해야 한다는 점도 확인했죠. 현재 이 기준으로 평가를 재수행할 예정이며, 결과는 모델 카드에 업데이트하겠습니다.
💡 모델 공개 정보
Ultra Diar Streaming Sortformer 8spk v1 (mago-ai/ultra_diar_streaming_sortformer_8spk_v1)
베이스 모델: nvidia/diar_streaming_sortformer_4spk-v2.1
확장: 4 → 8 화자
라이센스: Apache 2.0
HuggingFace에서 바로 사용 가능
학습 코드, NeMo 패치, 합성 데이터 툴링은 GitHub(mago-research/Ultra-Sortformer)에 함께 공개되어 있습니다.
📍 다음 단계: 한국어 특화 버전
이번에 공개한 모델은 다국어(multilingual) 기반입니다. MAGO 마고의 핵심 도메인인 한국어 환경에서의 성능을 끌어올리기 위해, 한국어 특화 파인튜닝 버전을 준비하고 있습니다.
한국어 대화의 특성 (짧은 발화, 잦은 끊김, 한영 혼용) 을 학습 데이터에 반영한 버전으로, 공개 일정은 추후 안내드리겠습니다.
📍 음성에서 정보를 꺼내는 기술
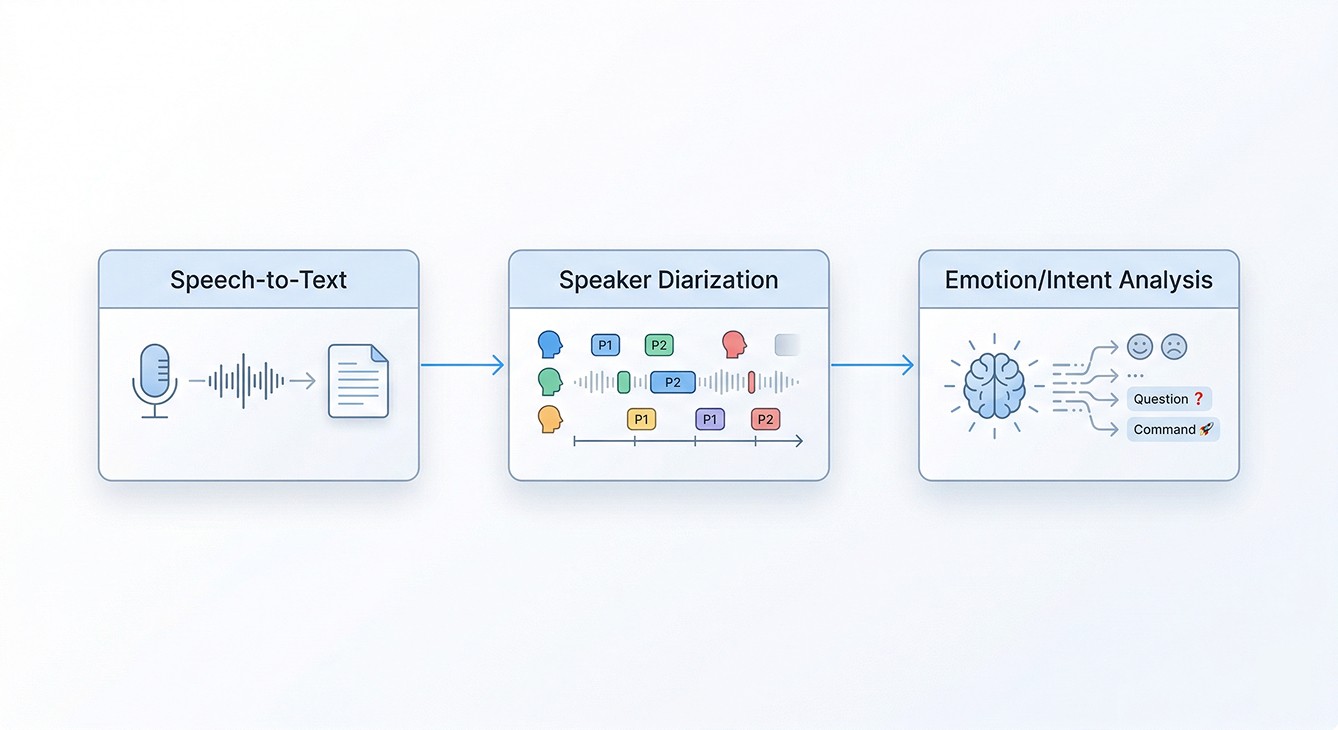
화자 분리는 단독으로 완결되는 기술이 아닙니다. STT로 무엇을 말했는지 파악하고, 화자 분리로 누가 말했는지 구분하고, 여기에 감정 분석(SER)과 의도 분석(Intent)이 더해질 때 음성 데이터를 실제로 분석에 쓸 수 있게 됩니다.
MAGO 마고는 이 파이프라인 전체를 단일 API로 제공하는 Audion을 운영하고 있습니다. 이번 오픈소스 공개는 그 기반 기술을 커뮤니티와 함께 검증하고 개선해가기 위한 것입니다.
다화자 음성 분석 도입을 검토 중이시거나, 기술적인 부분에 대해 더 이야기 나누고 싶으신 분은 언제든 마고에 문의해 주세요.