

There are situations you often encounter when applying voice AI in the field.
A call center has two people: an agent and a customer. What should you do when you're asked to analyze a roundtable recording with 8 or more participants?
High-performance E2E (End-to-End) speaker diarization models support only up to 4 speakers. From the 5th speaker onward, they are either treated as silence or merged into other speakers. pyannote, a clustering-based model, supports up to 10 speakers, but it has limitations in real-world deployment in terms of speed and performance in commercial environments. In the end, there was no E2E model that could support 8 or more speakers while delivering both speed and performance.
To solve this problem, MAGO started research and is now releasing the results.
🔎 What is Diarization?
Speaker diarization is the technology that automatically distinguishes "who said what and when." If STT is "dictation" that turns speech into text, speaker diarization is the process of putting name tags on that text. Only when the two are combined does it gain value as "conversation data."
Only when the two technologies are combined does it become a form that can be used in real business. In call center analysis, agent utterances and customer utterances must be separated so that each one's emotional state and response quality can be evaluated separately. In meeting transcripts too, if you cannot track "who said this," the meaning of the analysis drops significantly.
🧐 Why is 4 the limit?
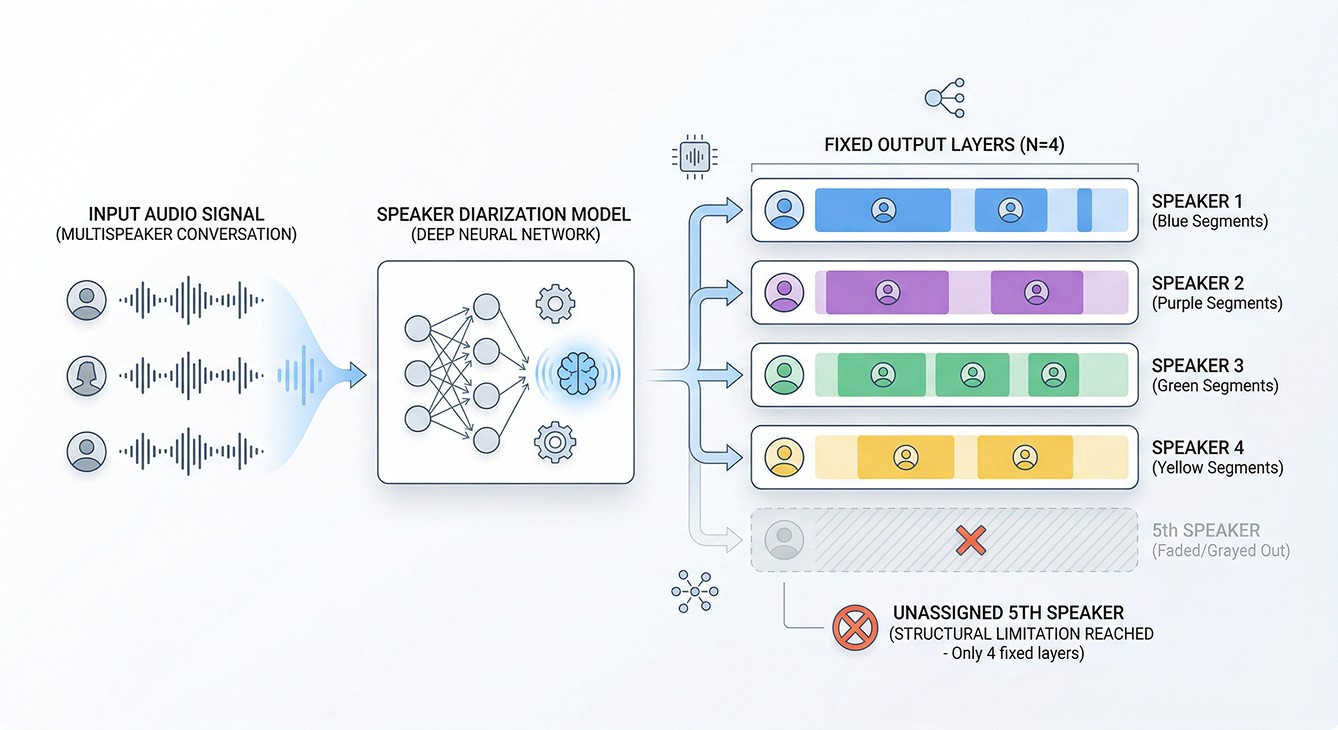
Current high-performance speaker diarization models are mostly designed for up to 4 speakers (4-speaker). NVIDIA NeMo's Streaming Sortformer model is no exception.
The reason is structural constraints. The model needs as many output layers as there are speakers, and increasing that requires architecture changes along with large-scale retraining. Above all, it is very difficult to secure real multi-speaker training data.
In the environments where MAGO actually provides services, cases with more than 4 speakers are not uncommon.
Corporate roundtables, educational content production environments: 8 or more
Call center channel integration: complex speaker compositions such as agents, customers, and ARS
Meeting transcription service: environments where multiple participants speak simultaneously
The 4-speaker limit becomes a problem immediately in these scenarios.
🔈 Expanding the number of speakers while maintaining existing performance
Based on NVIDIA NeMo's Streaming Sortformer, MAGO developed a model that supports up to 8 speakers.
The two hardest problems were data acquisition and preserving existing performance.
The training data problem was solved with synthetic data. Based on AI-Hub's multi-speaker speech synthesis data (over 3,400 Korean speakers, about 10,000 hours), we customized NeMo's data simulator to generate synthetic dialogue data with various numbers of speakers and utterance patterns. We also mixed in a small amount of data containing noise from real meeting environments to prevent overfitting to clean environments only.
The existing performance preservation problem was solved with two techniques.
First, instead of simply randomly initializing the newly added output layer, we used SVD-based Orthogonal Initialization. After decomposing the existing weight matrix with SVD, the new layer is initialized in a direction mathematically orthogonal to the representation space of the existing speakers. This minimizes the impact of the newly added speaker dimension on recognition of the existing 2- to 4-speaker setting.
Second, we applied different learning rates (Split Learning Rate) to the existing and new layers. The existing layers preserve pretrained representations with a low learning rate (1e-5), while the new layers are designed to quickly learn the new speaker range with a higher learning rate (1e-4).
🖇️ Discussion with the NVIDIA NeMo Speech team
After releasing this model on HuggingFace, we were contacted by the NVIDIA NeMo Speech team. The research team responsible for speaker diarization and speech recognition discovered MAGO's model and proposed technical discussions, and the two sides later discussed evaluation methodology, training data composition, multi-speaker streaming optimization strategies, and more.
In this process, we also gained important insights about the evaluation dataset. Some AMI RTTM files circulated on the internet can distort evaluation metrics because silence segments are mislabeled as speakers during the original XML conversion process. We confirmed that, for accurate evaluation, the correct RTTM files from the official distribution channel must be used. We plan to rerun the evaluation based on this standard, and will update the results in the model card.
💡 Model release information
Ultra Diar Streaming Sortformer 8spk v1 (mago-ai/ultra_diar_streaming_sortformer_8spk_v1)
Base model: nvidia/diar_streaming_sortformer_4spk-v2.1
Expansion: 4 → 8 speakers
License: Apache 2.0
Available directly on HuggingFace
The training code, NeMo patch, and synthetic data tooling are also available on GitHub (mago-research/Ultra-Sortformer).
📍 Next step: Korean-specific version
The model released this time is multilingual-based. To improve performance in the Korean environment, which is MAGO's core domain, we are preparing a Korean-specific fine-tuning version.
A version that reflects the characteristics of Korean conversation (short utterances, frequent interruptions, mixed Korean and English) in the training data is being prepared, and the release schedule will be announced later.
📍 Technology for extracting information from speech
Speaker diarization is not a self-contained technology. Only when STT identifies what was said, speaker diarization identifies who said it, and sentiment analysis (SER) and intent analysis (Intent) are added, can voice data actually be used for analysis.
MAGO operates Audion, which provides this entire pipeline through a single API. This open-source release is intended to validate and improve the underlying technology together with the community.
If you are considering introducing multi-speaker speech analysis or would like to discuss the technical aspects further, please feel free to contact MAGO anytime.
📌 View model on HuggingFace · GitHub code · Audion API inquiry