

In industries with many specialized terms, general-purpose STT often misrecognizes words by 1 to 2 syllables, and those small differences greatly affect work quality. Mago has stabilized the recognition of specialized terms by (1) reflecting terminology dictionaries and domain fine-tuning, and (2) applying LLM context-based post-processing corrections, successfully validating this in a corporate training content environment mixed with various professional domains over a long period.
One question that many corporate clients ask when they come to Mago is:
"Can you accurately recognize our industry terms as well?"
Names of semiconductor processes, chemical substances, pharmaceutical ingredients, internal system codes. These words rarely appear in everyday conversations. Therefore, they are often easily broken in general speech recognition (STT) models. The issue lies not in the model's 'performance' but in what the model has learned.
💡 Why do general-purpose STTs struggle with specialized terms?

Most global STT models are optimized for general data like everyday conversations, broadcasts, YouTube, and meeting audio. Whisper, Google, Microsoft, Meta. They are all excellent models trained on large-scale data.
Company | Method |
|---|---|
OpenAI | General model + Company implements domain-specific features directly |
Supports Custom Vocabulary | |
Microsoft | Supports Custom Speech Re-learning |
IBM | Custom words / grammar input |
AssemblyAI | API structure based on custom vocabulary |
ElevenLabs | Scribe v2 STT model + Keyterm Prompting |
Naver Clova | Registering specialized terminology based on Keyword Boosting + NEST speech recognition engine |
Return Zero | Whisper fine-tuning + proprietary STT engine + Keyword Boosting |
However, such models are strong in averages. They are not strong in specialized domains. For example, “Lithography process” may be split as “Liso graphy process” or “Polyimide” may be recognized as “Poly imide.” Completely incorrect cases are rare. Usually, it is 1 to 2 syllables that are misaligned. However, in a corporate environment, those 1 to 2 syllables can be critical.
💡 Why is specialized term recognition more important in enterprise environments?
Speech recognition errors can occur in any service. However, in enterprise environments, the impact is much greater. In consumer services, users often use features briefly and leave, so the impact of errors is relatively limited.
On the other hand, in a business environment, speech data accumulates continuously, and the results are used for search, analysis, reporting, and decision-making. If even one specialized term is misrecognized, that error can accumulate throughout the entire dataset.
At first, it may seem like a small typo, but when the data accumulates to thousands of records, it can lead to degraded search quality, analysis errors, and increased operational costs. Moreover, the more STT errors there are, the more attempts are made to correct them with LLM prompts, which can increase prompt length and calls, thereby increasing LLM costs and delays.
Therefore, in enterprise environments, the stability of specialized term recognition becomes a more important criterion than simple average accuracy.
🔎 So how did Mago approach this?
We changed the question from the beginning. Instead of asking, "Can we get it perfectly right?" we first asked, "Where is it going wrong?" The pattern was relatively clear.
The phonemes themselves are correct.
They are distorted at specific syllables.
They can be restored when looked at in context.
Therefore, Mago employs two methods simultaneously.
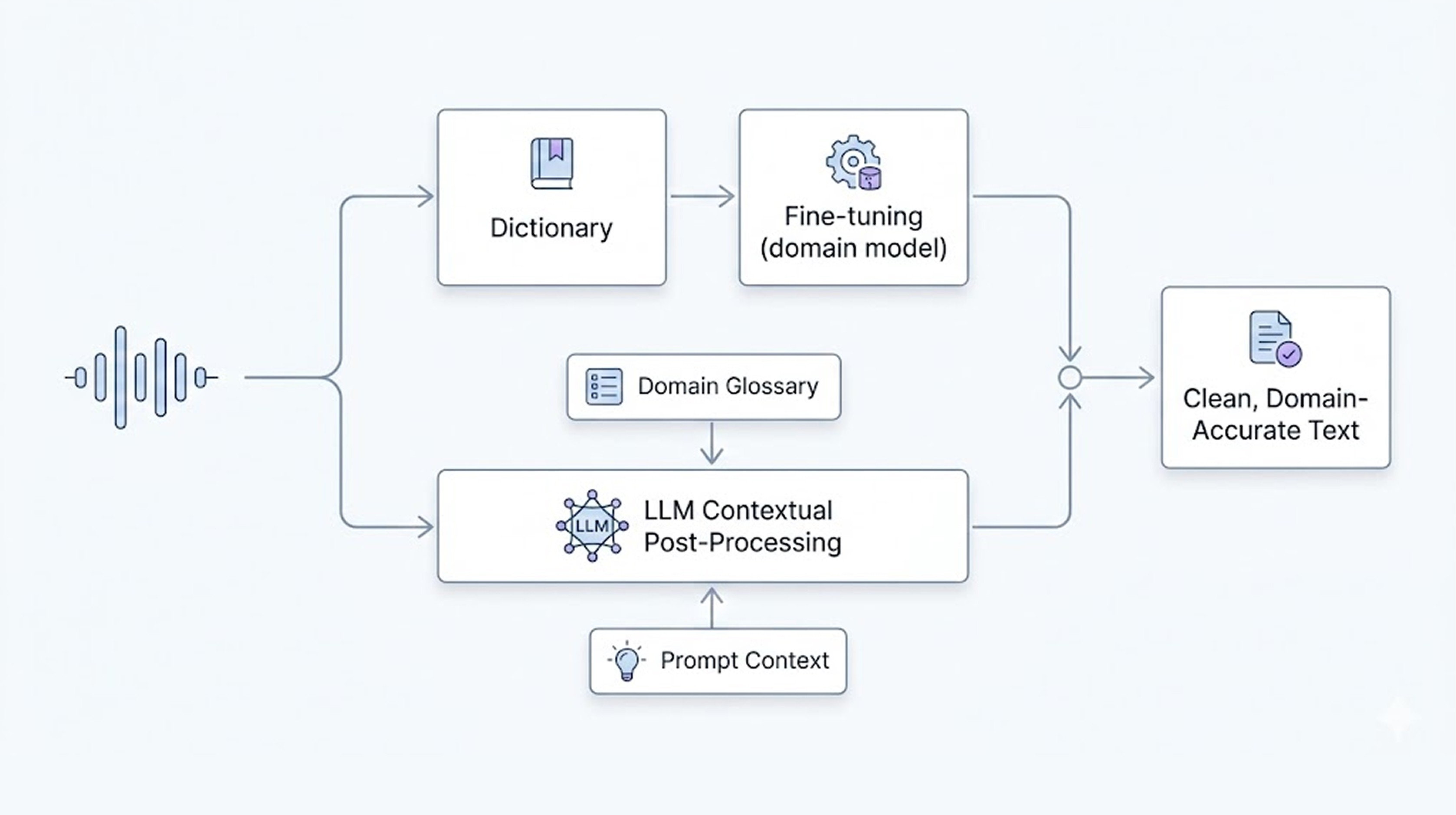
▶️ Method of reflecting in models
When there are terminology dictionaries, we reflect them directly in the model up to a few hundred units. This can be applied quickly and shows improvement effects even without fine-tuning. However, when the number increases to thousands, structural limitations arise. At that point, we create a domain-specific model.
Collecting domain speech data for over 10 hours
Fine-tuning the dedicated model
1 to 2 weeks of training
This method incurs costs, but it is the most reliable for long-term services.
▶️ Post-processing correction structure
Specialized terms mostly have slight deviations rather than being completely wrong. The Mago engine has been trained with tens of thousands of hours of Korean speech data, making phoneme-level recognition quite stable. Therefore, we combine it with LLM-based post-processing.
Input domain dictionaries
Add industry information prompts
Context-based restoration
By using this structure, we can effectively improve accuracy without creating an entirely new model.
🖇️ Was it really possible?
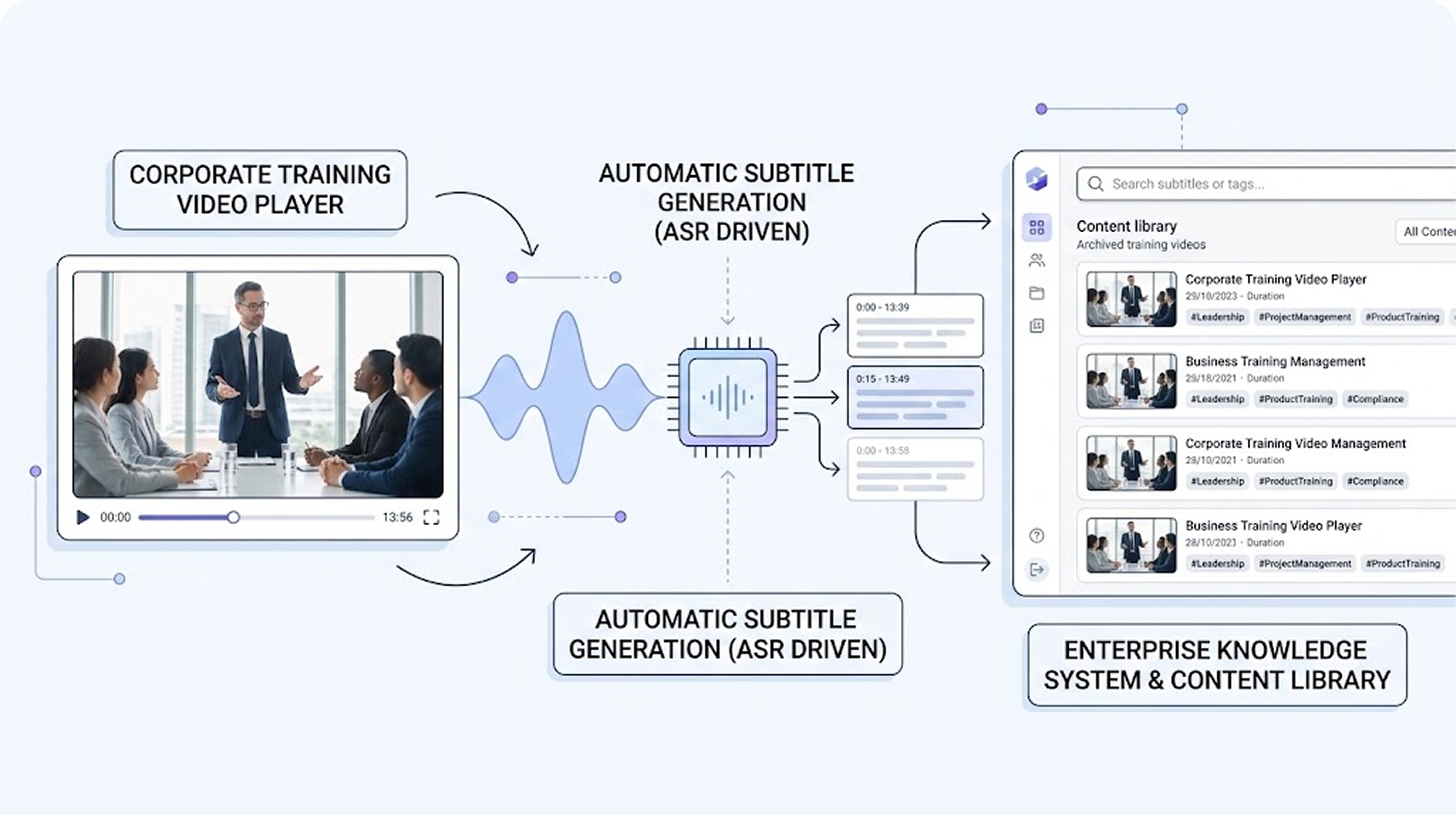
From 2023 onwards, for two years, Mago supplied its self-developed STT for automatic subtitle generation in SK Group's in-house training videos. Semiconductor, chemical, and complex business domains. It was an environment mixed with entirely different specialized terms. This project demonstrated one thing.
Domain-specific STT is not just a theoretical problem but an operational structure issue. It cannot be resolved with just one model; it requires a combination of domain reflection + correction + operational experience to function stably. It is not about whether the model is big or small.
A structure that can reflect domain knowledge
A design that can be re-trained
Context-based corrections
Real industrial operational experience
With these four components, we can have STT that is usable in enterprise environments. And at the root of this problem lies the structural difficulties inherent in Korean STT. In the next article, we will delve deeper into why Korean STT is challenging.
🔈 If you are considering applying STT in an environment with many specialized terms, your approach strategy will change based solely on the industry and data types. Feel free to talk with Mago.