

When dealing with speech recognition (ASR/STT) technology, we often receive questions in the field, such as, "Why is the error rate of Korean STT higher than that of English?"
In fact, the error rate (WER) of Korean speech recognition is generally 1.5 to 3 times higher than that of English. It is easy to think that this gap is simply due to a lack of data, but practically, the linguistic structure of Korean is also a major reason.

Source: https://elevenlabs.io/speech-to-text/english

Source: https://elevenlabs.io/speech-to-text/korean
*WER is 10.7, which is about 3 times higher compared to English
🧐 Technical Reasons Why Korean Speech Recognition is Challenging
There are several distinct characteristics that form the barriers to Korean encountered in the field.
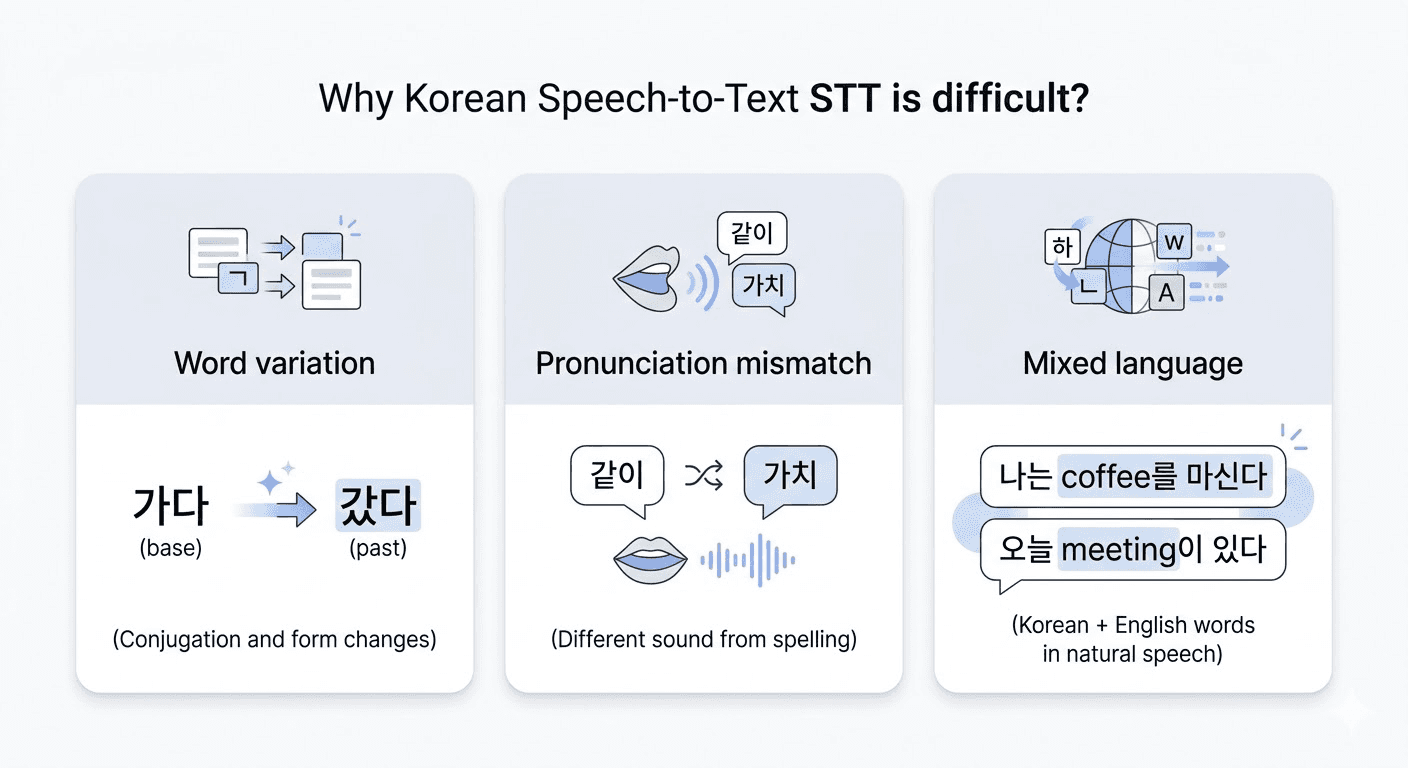
Variable Word Structure (Agglutinative Language): In English, words are relatively independent, but Korean is an agglutinative language where particles and endings continuously combine after the root. Even a single word like
가다can have many forms like갔다, 갔었다, 갔었습니다. The Standard Korean Dictionary alone has over 510,000 words, and when considering loanwords and morpheme analysis, the information volume for the model to process becomes immense.Mismatch Between Notation and Pronunciation (Phonological Changes): In Korean, as in
국밥[국빱],같이[가치], there are often cases where the actual spoken words do not match the written ones. If these pronunciation rules (phonological laws) are not meticulously reflected when converting voice signals to text, it leads to misrecognition. Though English also has irregular pronunciations, Korean's phonological changes are much more extensive and systematically operate, making the learning difficulty higher for the model.Increase in the Proportion of Foreign Words and English Mixing: To process English words, a Korean model must understand the pronunciation systems of both languages simultaneously. Additionally, the same foreign word may have different pronunciations among speakers (marketing vs 마게팅, data vs 데이타), making consistent recognition even harder.
🔎 How MAGO Designs Speech Models
There are commonalities among the three problems. While more data always helps, merely increasing the amount of data does not solve the issue. Performance does not improve proportionally with quantity alone. MAGO focuses on incorporating the linguistic structure of Korean and the characteristics of voice signals from the design stage of the model.
MAGO begins from this point.
Voice Optimization Design: We have built an embedding model that captures the complex phonological changes in Korean.
Speech Signal Preprocessing: Through speech enhancement and separation technology that precisely isolates voices from noise, we maintain stable accuracy in performance.
Korean Custom Tokenizer: We use a method that segments and processes words by reflecting the morphological properties of our language.
🔈 STT, The Next Phase
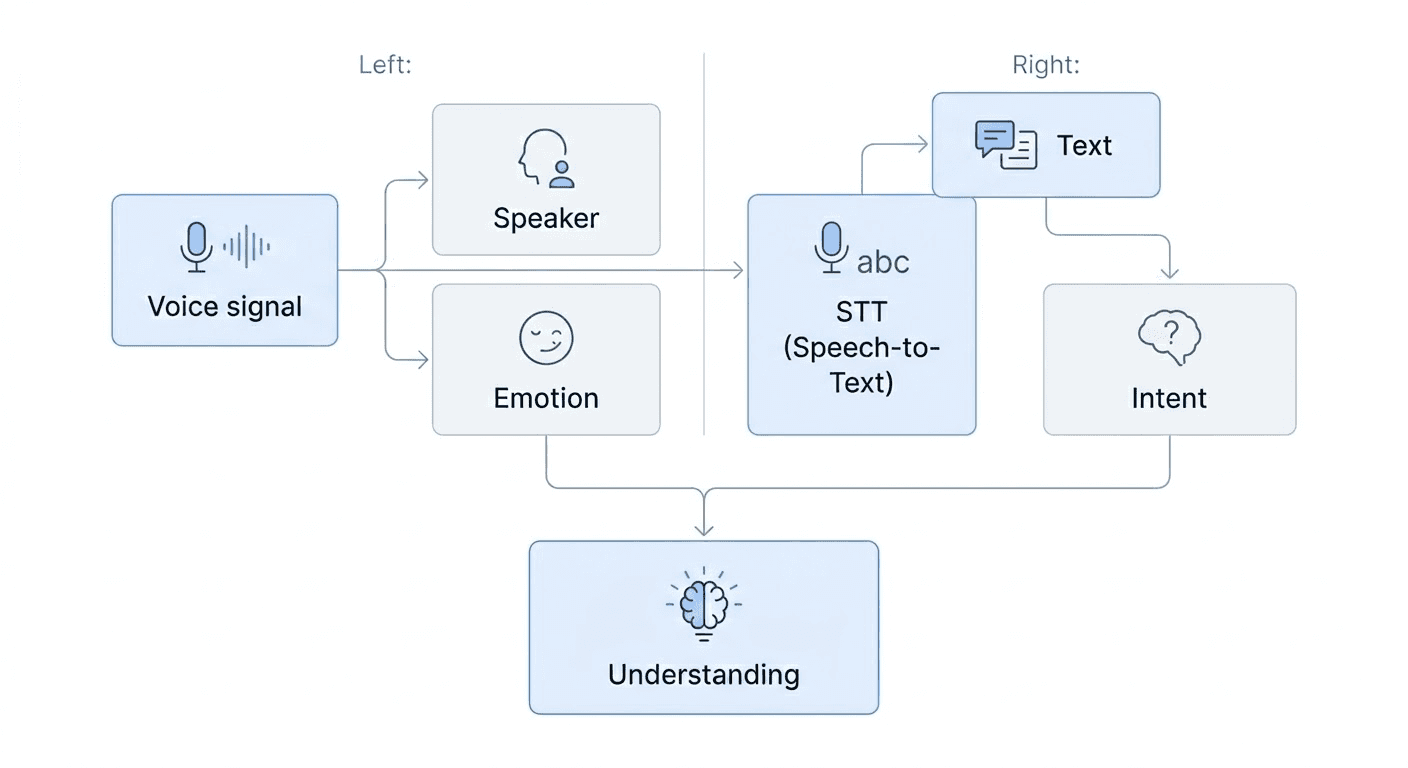
While many speech recognition services focus on STT accuracy, in actual business settings, text accuracy alone may not be sufficient. This is because data like "who spoke (speaker information, Diarization)" and "what tone was conveyed (Emotion)" are used to enhance the precision of analysis to clearly understand the context of conversations.
MAGO aims for 'Voice Understanding,' which provides multidimensional information necessary for businesses by analyzing voice data from various perspectives, while being based on stable recognition performance.
Information such as speaker separation and emotion analysis is extracted directly from the signal, and the intent of the conversation is identified from the analyzed text. For reliable analysis results, each piece of data must be organically interconnected.
💡 Technology to Understand Voice as It Is
The challenges of Korean STT are not only due to the lack of data but also because the structure of Korean and the voice signals themselves are complex. Ultimately, the core of technical strength lies in how these characteristics are integrated into model design.
MAGO creates solutions that go beyond simple transcription to uncover information valuable to businesses from voice data.
Are you considering implementing speech recognition suitable for the Korean environment? If you are contemplating specific application methods or technical optimization, feel free to discuss them with MAGO anytime!